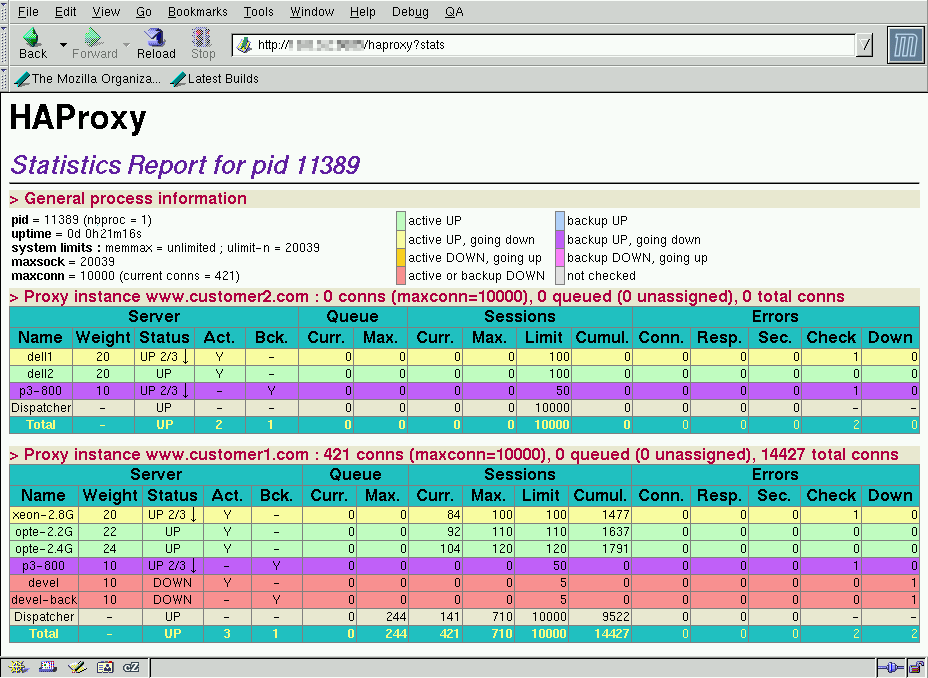
Quick links
Quick NewsDescription
Design Choices
Supported Platforms
Performance
Reliability
Security
Download
Documentation
Live demo
Commercial Support
Products using HAProxy
Contributions
Other Solutions
Contacts
Mailing list archives
Willy TARREAU
Benchmarks using Myricom's PCI-Express 10 Gig NICs (Myri-10G PCI-Express)
...or how to achieve 10-Gig load-balancing with HAProxy !Lab setup
-
The 4 high performance NICs are installed in 3 machines. In order to be
able to run enough experiments on chipset performance, I selected the following
motherboards :
- ASUS M3A32MVP Deluxe + AMD Athlon64-X2/3.2 GHz for traffic generation (*2)
- ASUS P5E + intel C2D E8200/2.66 GHz to host HAProxy
The reason for the P5E is that it runs the extremely fast intel x38 chipset which already runs my other PC. From previous tests, I *knew* it was fast enough for 10 Gbps full-duplex.
Well, I was right to select two different boards. The AMD-based mobos cannot push more than 8-9 Gbps to the wire. They can receive it though. For this reason, some of the tests are made with my desktop PC as the HTTP server (x38 too), so that the whole chain is not limited to 10 Gbps.
I could also verify that this wonderful intel X38 chipset has no trouble pushing 20 Gbps to the wires when attacked by both AMD in parallel.
Anyway, whatever the test, the client is always directly connected to the HAProxy, which itself is directly connected to the server. Those are only point-to-point connections, as I have no 10-Gig switch.
Tests methodology
-
The tests are quite simple. An HTTP request generator runs on the first Athlon
(amd1). HAProxy runs on the Core2Duo (c2d). The TUX kernel-based
web server runs on another machine (either amd2 or my PC). A script calls
the request generator for object size from 64 bytes to 100 megs. The request generator
continuously connects to HAProxy to fetch the selected object from TUX in loops for 1
minute. Statistics are collected every second, so we have 60 measures. The 5 best ones
are arbitrarily eliminated because they may include some noise. The next 20 best ones
are averaged and used as the test's result. This means that the 35 remaining values
are left unused. This is not a problem because they include values collected during
ramping up/down. In practise, tests show that using 20 to 40 values report the same
results.
-
The collected values are then passed to another script which produces a GNUPLOT script,
which when run, produces a PNG graph. The graph shows in green the number of hits per
second, which also happens to be the connection rate since haproxy does only one hit
per connection. In red, we have the data rate (HTTP headers+data only) reached for
each object size. In general, the larger the object, the smaller the connection
overhead and the higher the bandwidth.
Tests in single-process mode, 16kB buffers
-
This first test is the "default" one. It is a standard haproxy running on the C2D.
Client is amd1, server is TUX running on my PC (X38), proxy is running on
C2D with X38 too. 20 object sizes from 64 bytes to 100 megs have been
iterated :
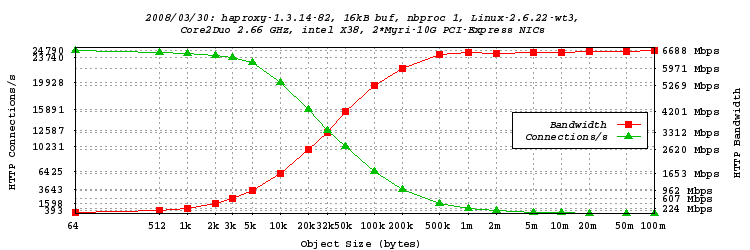
-
We see that with only one process, we cannot go higher than 6.688 Gbps of forwarded HTTP
traffic. Half of that is reached with 32 kB objects. The Gbps is attained with objects
larger than 6 kB approxy. 4 Gbps are already attained with 50kB objects (more than
10000 connections/s). The peak connection rate is at 24790 connections/s, which is
already not bad at all.
Tests in dual-process mode, 16kB buffers
-
Since the C2D has 2 cores, it was interesting to see how the machine performed with 2
processes. The nbproc parameter was set to 2, and tune.maxaccept to
only 1 to ensure that requests would be equally spread over both cores. Both network
interrupts (218 and 219) were assigned to a different CPU core to avoid cache line
bouncing, since the C2D does not have a unified cache like the Athlon has. Client is
still amd1, and server is still TUX running on my PC (X38). The test is
exactly the same as previous one.
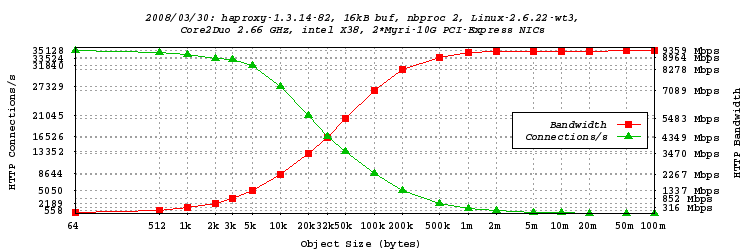
-
We see that with two processes this time, we reached 9.359 Gbps. That's very
close to line-speed. Those Myri-10G NICs are really amazing! The system does about
73000 full-buffer reads and 73000 full-buffer writes every second, so the buffer
size has a significant impact here. Fro this reason, another set of tests will be
run with >60 kB buffers. We also notice that higher rates are attained with smaller
objects than with one process. 32 kB objects already surpass 4 Gbps, and the Gbps
is already exceeded around 4kB objects. It's also worth noting that the connection
rate reached 35128 hits/s! Last record broken!
Tests in dual-process mode, 63kB buffers
-
As indicated above, we are dealing with very high read/write rates, so it may be worth
expanding the buffers. Since the NICs are using jumbo frames by default (9kB), I
set the buffer size to 63 kB (7 frames). OK, it should have been 62720 bytes to
accommodate the MSS, but that's not really a problem...
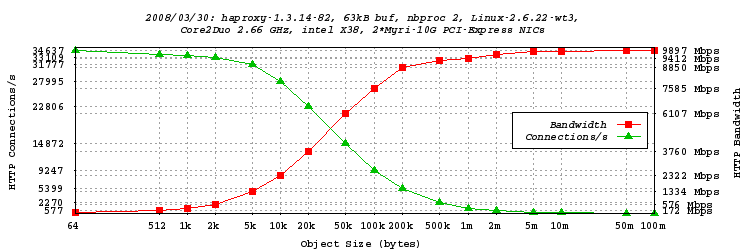
-
The performance is even better, a new record is set with 9.897 Gbps of HTTP traffic!
We're now above 6 Gbps for 50kB objects. Unfortunately, some values have not been tested, so
this test will be re-run soon. We also notice that the absolute maximum connection
rate is slightly lower than with smaller buffers. This is most likely caused by the
cache thrashing more with larger buffers.
Preliminary conclusion
-
Those NICs work amazingly well. Even better than I would have imagined. Also, while
they do no magics, they put very little stress on the system (I suspect the driver
is of excellent quality). At 20 Gbps with TUX, CPU was 85% idle!
I also noticed the connection rate jumping from 55000 hits/s to 68000 hits/s by
simply routing via the 10 Gig NIC instead of the 1 Gig one (the wire was far from
being saturated).
-
Too bad the AMD-based mobos cannot push enough data on the wire. I suspect the
AMD790FX chipset is simply buggy. In fact, if I overclock the PCI-E bus, I
get the exact same ratio of additional bandwidth. Unfortunately, the system
is unstable over 12%, and that's not enough to saturate the wire. This is a
PCI-E 2.0 bus, and I tried playing with a lot of parameters with no luck. Also, the
card is not detected if plugged into one of the two blue PCI-E slots (1 and 3). I
also noticed that when used in full-duplex operation, the motherboard saturates at
about 12 Gbps IN+OUT. If I had to buy new mobos, now I would definitely go for P5E
only. At least I have experimented.
-
Next research directions will focus on dynamic buffer allocation, along with
experimentations on MTU. Right now it's 9000, and I noticed the bit rate
halving at 1500. But having 5 Gbps of traffic at 1500 handled by such a cheap box
is already excellent !
Contacts
Feel free to contact me at for any questions or comments :
- Main site : http://1wt.eu/
- e-mail :